KeypointNeRF is a generalizable neural radiance field for virtual avatars.
Abstract
Image-based volumetric avatars using pixel-aligned features promise generalization to unseen poses and identities. Prior work leverages global spatial encodings and multi-view geometric consistency to reduce spatial ambiguity. However, global encodings often suffer from overfitting to the distribution of the training data, and it is difficult to learn multi-view consistent reconstruction from sparse views. In this work, we investigate common issues with existing spatial encodings and propose a simple yet highly effective approach to modeling high-fidelity volumetric avatars from sparse views. One of the key ideas is to encode relative spatial 3D information via sparse 3D keypoints. This approach is robust to the sparsity of viewpoints and cross-dataset domain gap. Our approach outperforms state-of-the-art methods for head reconstruction. On human body reconstruction for unseen subjects, we also achieve performance comparable to prior art that uses a parametric human body model and temporal feature aggregation. Our experiments show that a majority of errors in prior work stem from an inappropriate choice of spatial encoding and thus we suggest a new direction for high-fidelity image-based avatar modeling.
Highlights
Our key idea is to leverage keypoints as a universal representation for articulated objects to predict pixel-aligned neural radiance fields representing volumetric avatars. Given estimated keypoints and a query point, we propose a novel relative spatial encoding that anchors pixel-aligned features.
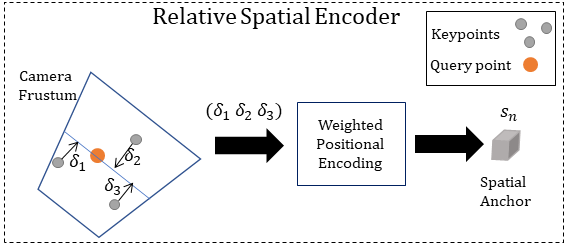
The benefit of this powerful representation is three-fold:
1) Generalization to Novel Identity: It enables learning human-specific prior that is leveraged to reconstruct unseen humans:
2) Generalization to Novel Capture System: The relative spatial encoding allows not only generalization to unseen identities, but also to novel capture systems (e.g. in-the-wild IPhone cpatures) without fine-tuning:
3) Universality: As a universal representation, KeypointNeRF can be directly used to reconstruct other articulated classes (e.g. humans) without any algorithmic modifications and generalize to novel identities and views:
Paper

BibTex
@inproceedings{Mihajlovic:KeypointNeRF:ECCV2022,
title = {{KeypointNeRF}: Generalizing Image-based Volumetric Avatars using Relative Spatial Encoding of Keypoints},
author = {Mihajlovic, Marko and Bansal, Aayush and Zollhoefer, Michael and Tang, Siyu and Saito, Shunsuke},
booktitle={European conference on computer vision},
year={2022},
}




