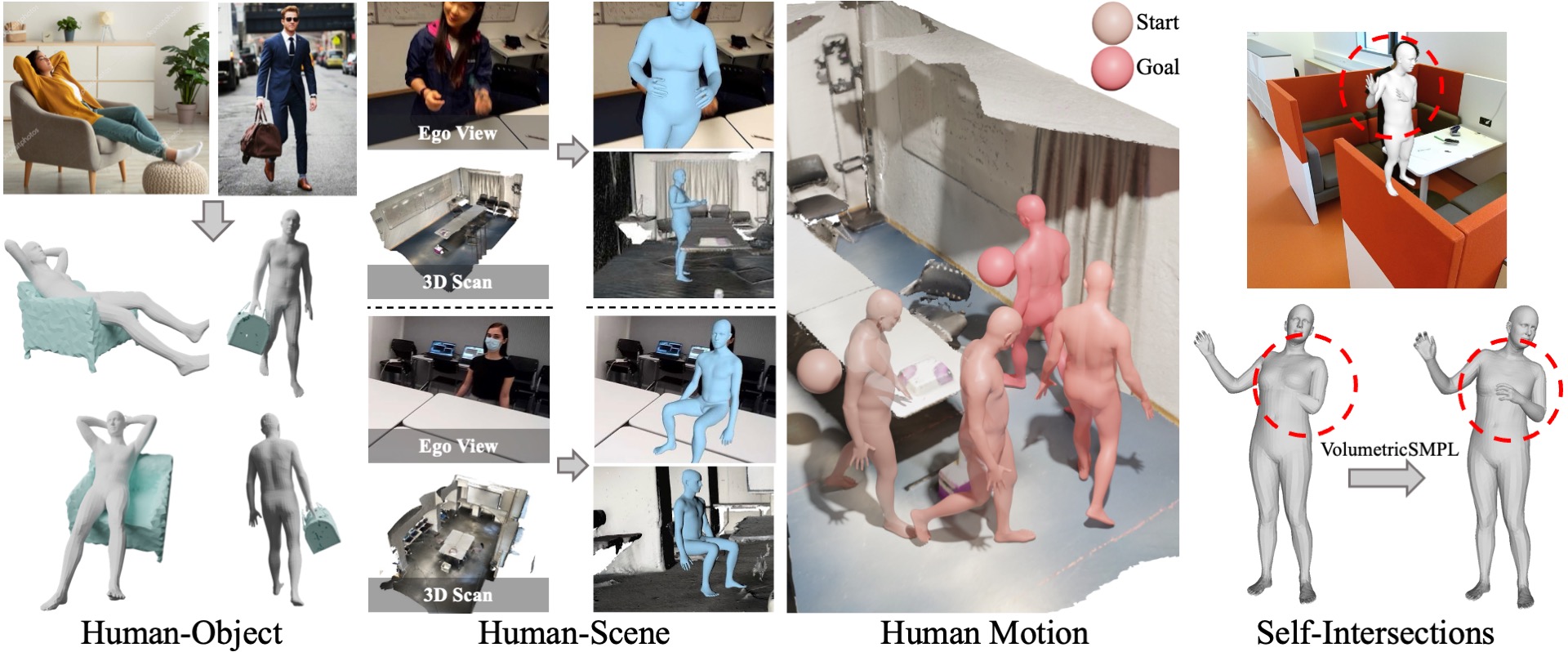
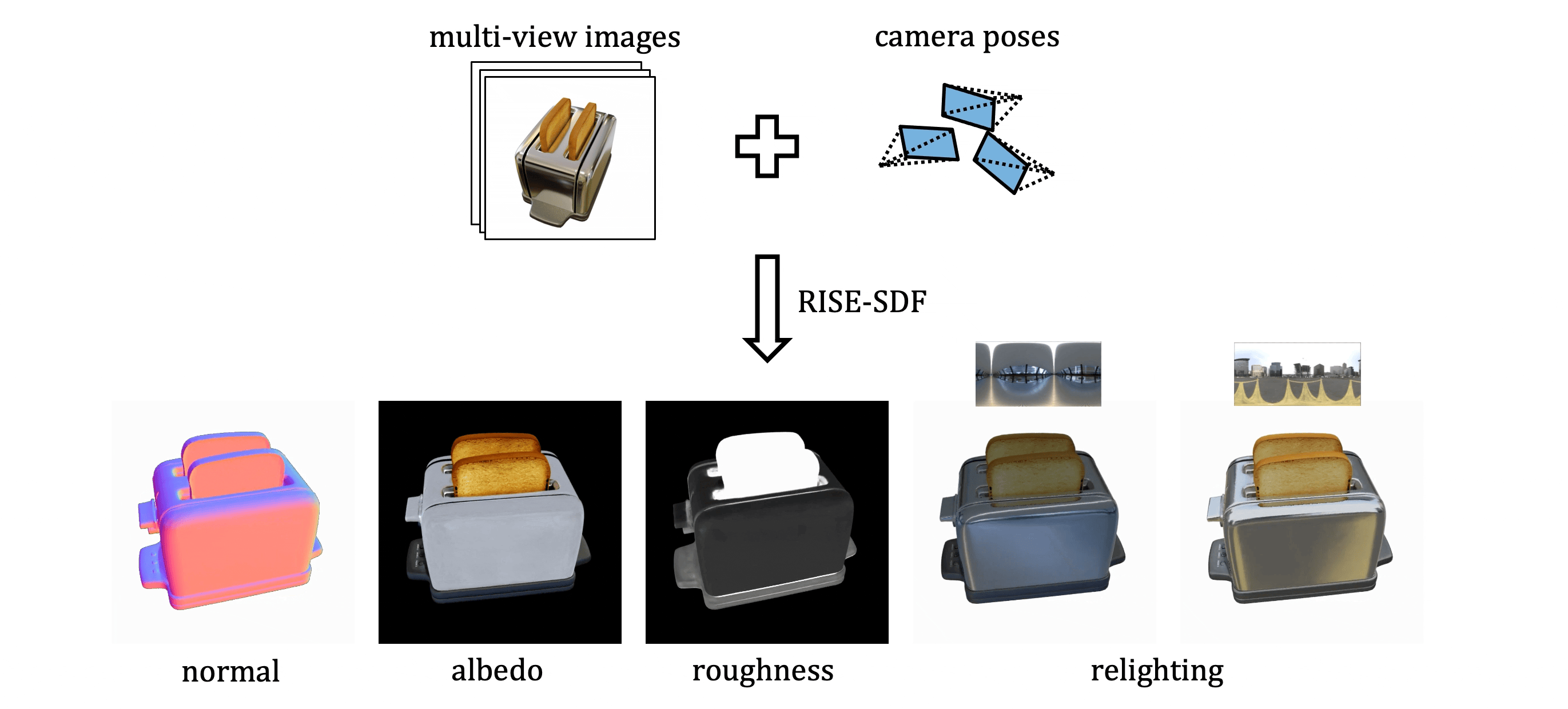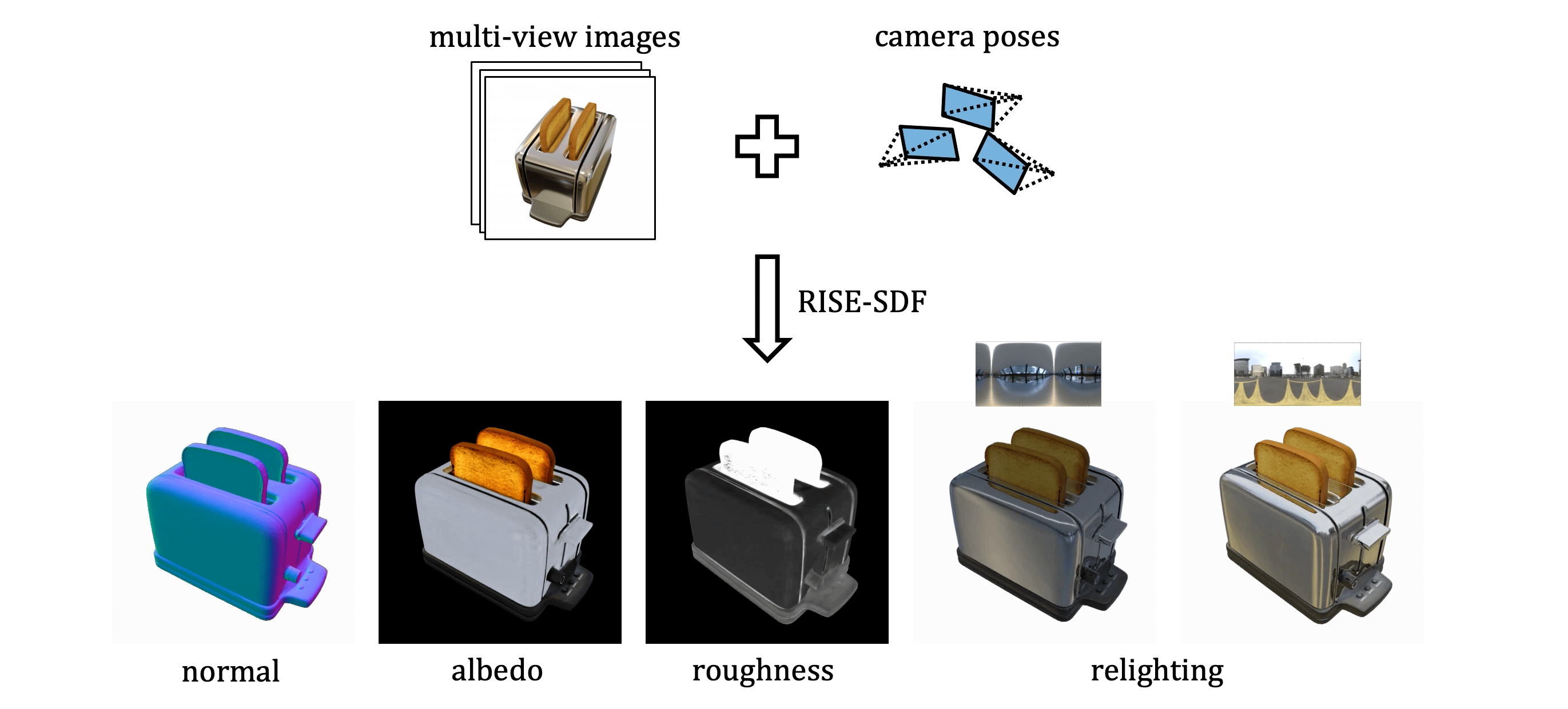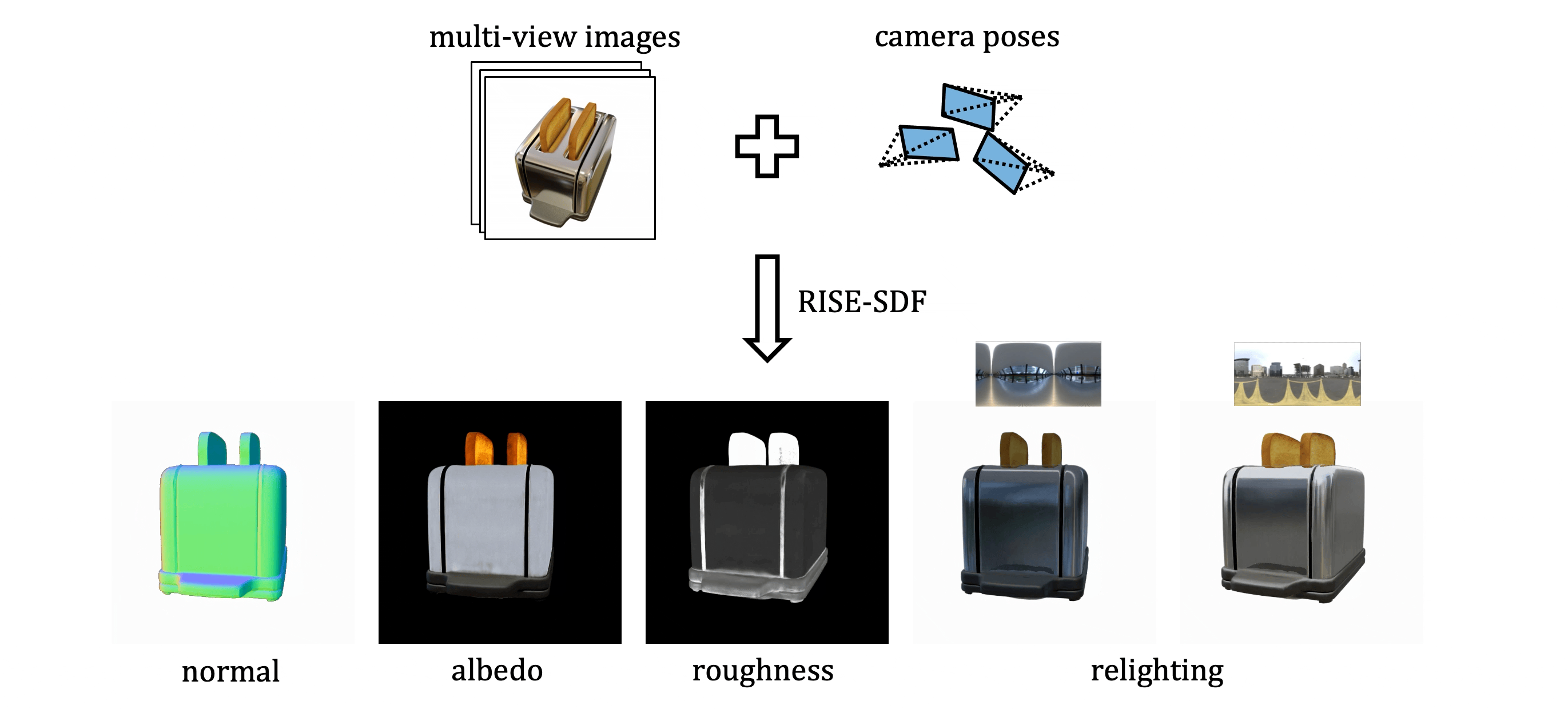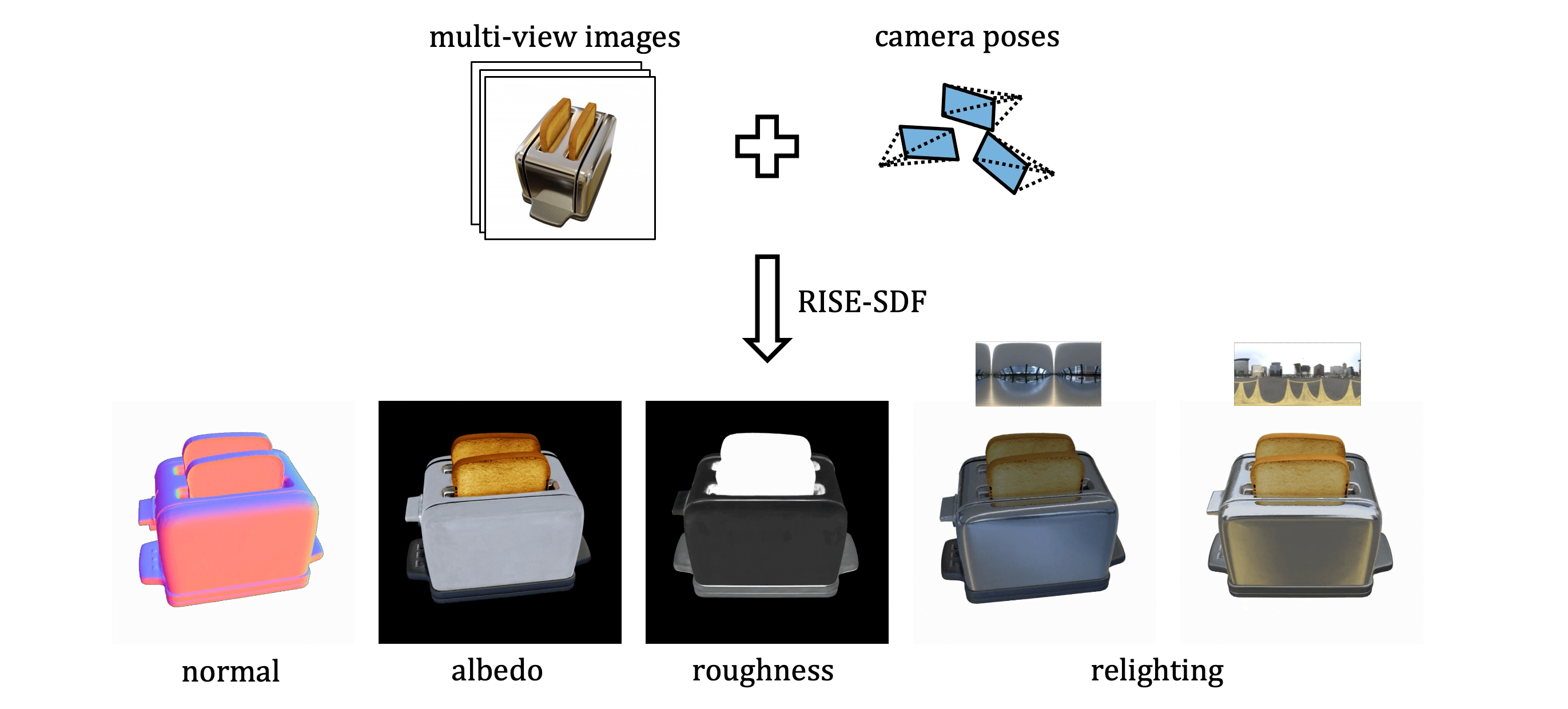
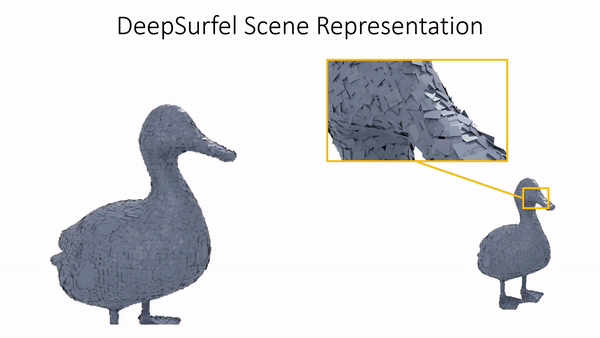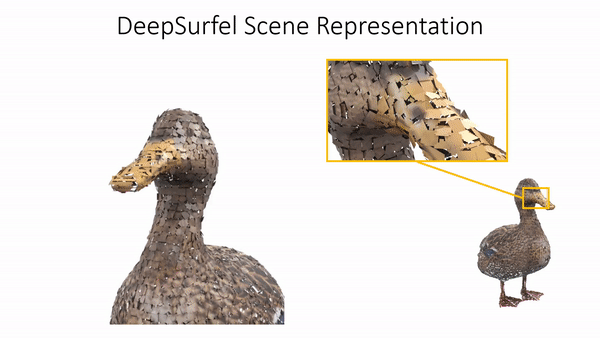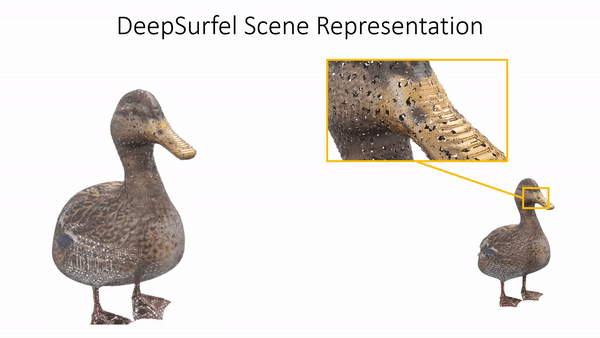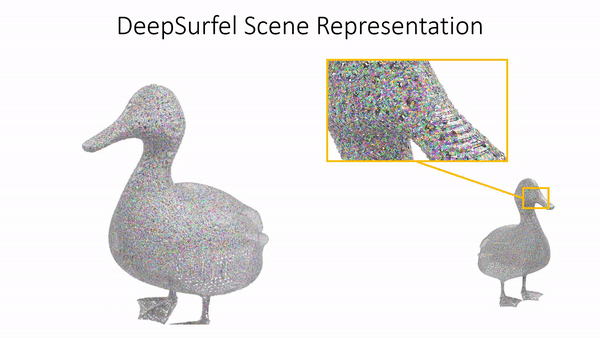
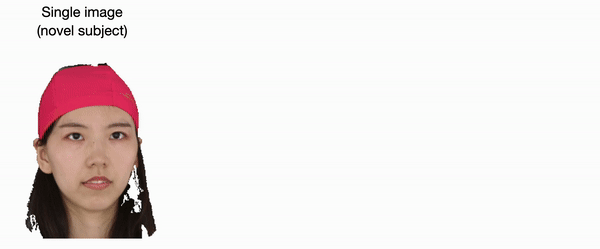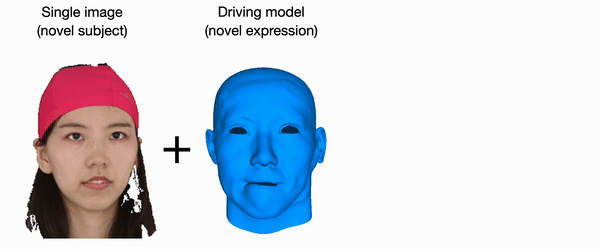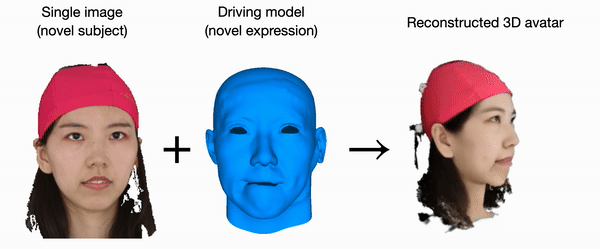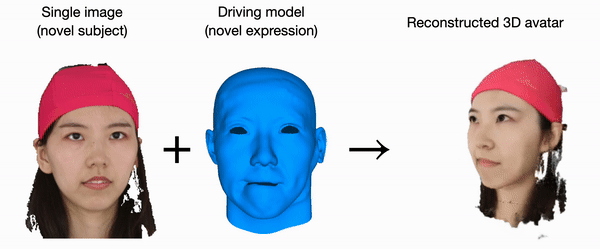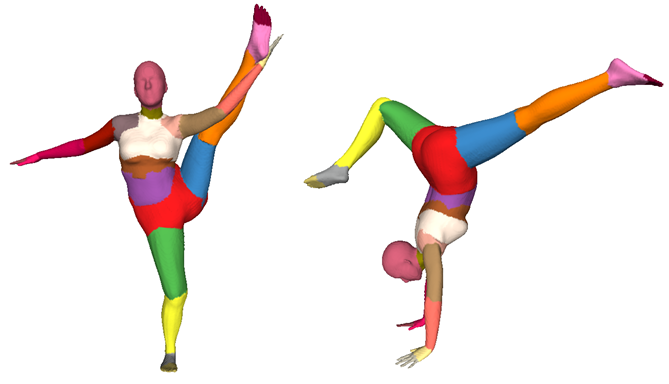Marko Mihajlovic
I’m a researcher at Apple’s Research team led by Vladlen Koltun. Before joining Apple, I completed my PhD in Computer Science at ETH Zurich with Siyu Tang and Marc Pollefeys and spent over a year at Meta in Zurich and Pittsburgh, working on immersive digital representations. My research focuses on developing systems that reconstruct the world’s structure and dynamics from visual inputs to enable precise digital replicas, with the broader goal of enhancing machines’ ability to perceive and interact with their surroundings using minimal inputs.